大阪大学大学院医学系研究科
呼吸器・免疫内科学
Department of Respiratory Medicine and Clinical Immunology, Graduate School of Medicine, The University of Osaka
| 抄録(Abstract) | 試験デザイン(Design),方法(Method),結果(Result),結論(Conclusion)による構造化抄録 |
| 背景(Background) | 科学的背景, 論拠(Rationale), 仮説 |
| 方法(Method) | 試験デザイン, 参加者の適格基準(Eligibility criteria), 事前に定義された主要・副次的アウトカム, 症例数設定の根拠, ランダム化(Randomization)・ブラインディング(Blinding)の詳細、主要・副次的アウトカムの比較に用いられた統計学的手法 |
| 結果(Result) | ランダム割付けされた人数,意図された治療を受けた人数,主要アウトカムの解析に用いられた人数, 追跡不能例とランダム化後の除外例と理由(フローチャートの推奨), 各群のベースライン・データ, 主要・副次的アウトカムの各群の結果,介入のエフェクトサイズの推定とその精度(95%信頼区間など), 各群のすべての重要な害(Harm)または意図しない効果 |
| 考察(Discussion) | 試験の限界,可能性のあるバイアスや精度低下の原因, 一般化可能性(外的妥当性,適用性), 結果の解釈,有益性と有害性のバランス,他の関連するエビデンス |
| その他 | 試験の登録, プロトコル, 資金源 |


| 目的変数 | 単変量解析 | 多変量解析 |
|---|---|---|
| 連続 | ①t検定 ②分散分析 ③Wilcoxon順位和検定 |
⑧多重線形回帰分析(重回帰) |
| 二値 | ④独立性検定 ⑤リスク比・オッズ比 ⑥割合の検定 |
⑨ロジスティック回帰分析 |
| 時間依存性 | ⑦ログランク検定 | ⑩コックス比例ハザードモデル |
| 2つの連続変数の関連 |
|---|
| ⑪相関係数(Pearson, Spearman, Kendall) |
| その他の多変量解析 |
|---|
| 主成分分析、判別分析、クラスター分析、パーティション解析など |
先行研究において、A群: 8.8±3.2、B群: 12.2±3.2であり、効果の大きさΔ=12.2-8.8=3.4、共通SD=3.2。検定の条件を、α=0.05(有意水準5%)、1-β=0.80(検出力80%)と設定。
サンプルサイズの公式より、群あたり15例となる。
N=2(Zα+Zβ)2 / (Δ/SD)2 + Zα2/4
=2(1.96+0.842)2/(3.4/3.2)2 + 1.962/4
=14.9
α=0.05(有意水準5%)、1-β=0.80(検出力80%)において、2群の割合の比較での必要症例数(群あたり)は以下のとおり。
| 70% | 50% | 30% | 10% | |
| 90% | 61 | 19 | 10 | 6 |
| 70% | 94 | 23 | 10 | |
| 50% | 94 | 19 | ||
| 30% | 61 |
| 群 | 値 | 要約 |
|---|---|---|
| A | 100, 110, 120, 120, 130, 130, 130, 140, 140, 150, 160 | 130±5.2, n=11 |
| B | 80, 90, 100, 100, 110, 110, 110, 120, 120, 130, 140 | 110±5.2, n=11 |

推定:平均値の差、20 [4.5, 36] (点推定と区間推定)
検定:p値は0.014(t検定、両側)
解釈:差があるとみなす
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 要約 | |
|---|---|---|---|---|---|---|---|---|
| 前 | 63 | 55 | 42 | 42 | 50 | 62 | 42 | / |
| 後 | 41 | 43 | 44 | 42 | 38 | 44 | 50 | / |
| Δ | -22 | -12 | 2 | 0 | -12 | -18 | 8 | -7.7±11.2, n=7 |

推定:Δの平均値、-7.7 [-18.1, 2.6]
検定:p=0.12(t検定、両側)
解釈:差があるとはいえない
| 群 | 値 | 要約 |
|---|---|---|
| A | 100, 110, 120, 120, 130, 130, 130, 140, 140, 150, 160 | 130±5.2, n=11 |
| B | 80, 90, 100, 100, 110, 110, 110, 120, 120, 130, 140 | 110±5.2, n=11 |
| C | 90, 100, 110, 110, 120, 120, 120, 130, 130, 140, 150 | 120±5.2, n=11 |

検定:p=は0.038(分散分析、自由度調整R2乗 0.14)
解釈:3群の平均値に差があるとみなす
検定:p=0.029(AvsB), 0.38(AvsC), 0.38(BvsC)
解釈:A-B群の平均値に差があるとみなす
検定:調整なしp=0.011(AvsB), 0.19(AvsC), 0.19(BvsC)、検定数(3)を乗じ
調整ありp=0.033(AvsB), 0.57(AvsC), 0.57(BvsC)
解釈:A-B群の平均値に差があるとみなす
| 群 | 値 | 要約(中央値・四分位範囲) |
|---|---|---|
| A | 20, 20, 28, 30, 32, 34, 40, 40, 50, 60, 70 | 34 [28, 50], n=11 |
| B | 20, 30, 40, 50, 50, 58, 60, 62, 64, 70, 80 | 58 [40, 64], n=11 |
 (箱ひげ図、ボックスプロット)
(箱ひげ図、ボックスプロット)
検定:p=0.065(Wilcoxon順位和検定)
解釈:差があるとはいえない
| 群 | 値 | 要約 |
|---|---|---|
| A | 20, 20, 28, 30, 32, 34, 40, 40, 50, 60, 70 | 34 [28, 50], n=22 |
| A追加 | 20, 20, 28, 30, 32, 34, 40, 40, 50, 60, 70 | |
| B | 20, 30, 40, 50, 50, 58, 60, 62, 64, 70, 80 | 58 [40, 64], n=22 |
| B追加 | 20, 30, 40, 50, 50, 58, 60, 62, 64, 70, 80 |
検定:p=0.008(Wilcoxon順位和検定)
解釈:差があるとみなす
③と③’は同じ要約値であるが、例数が多いと統計学的有意になる。実質的に意味のある差かどうか、意味のある差に対して適切なサンプル数が用いられているかをよく考える必要がある。
| 因子 | イベントあり | イベントなし |
|---|---|---|
| A | 45 | 55 |
| B | 30 | 70 |
検定:p=0.028(χ2乗近似による独立性検定)
p=0.041(Fisher正確確率法)
解釈:因子とイベントは独立でない(因子とイベント発生は関連があるとみなす)
| 因子 | イベントあり | イベントなし | リスク | オッズ | リスク比 | オッズ比 |
|---|---|---|---|---|---|---|
| A | 45 | 55 | 0.45 | 0.82 | 1.5 | 1.9 |
| B | 30 | 70 | 0.30 | 0.43 |
リスク(発症率/罹患率/Incidence):45/100=0.45(A群)、30/100=0.30(B群)
オッズ:45/55=0.82(A群)、30/70=0.43(B群)
推定:リスク比(RR: relative risk)1.5 [1.03, 2.18]
オッズ比(OR: odds ratio)1.9 [1.06, 3.42]
解釈:AはBに比してイベントのリスクが高い、またはイベントのオッズが高いとみなす
| 因子 | 事象数 | 観察数 | 割合 |
|---|---|---|---|
| A | 45 | 100 | 0.45 |
| B | 30 | 100 | 0.30 |
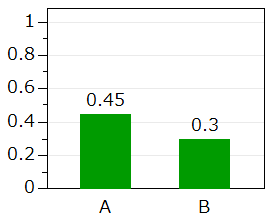
推定:割合の差 0.15 [0.016, 0.28]
検定:p=0.028
解釈:2群の割合に差があるとみなす
| 群 | ID | 時間 | 打切 | N | 故障率 | 生存率 | 累積 |
|---|---|---|---|---|---|---|---|
| A | 1 | 5 | 0 | 8 | 0.125 | 0.875 | 0.875 |
| 2 | 15 | 1 | 7 | ||||
| 3 | 20 | 1 | 6 | ||||
| 4 | 25 | 0 | 5 | 0.200 | 0.800 | 0.700 | |
| 5 | 30 | 1 | 4 | ||||
| 6 | 35 | 1 | 3 | ||||
| 7 | 40 | 1 | 2 | ||||
| 8 | 40 | 1 | 1 | ||||
| 群 | ID | 時間 | 打切 | N | 故障率 | 生存率 | 累積 |
| B | 9 | 5 | 0 | 8 | 0.125 | 0.875 | 0.875 |
| 10 | 10 | 0 | 7 | 0.286 | 0.714 | 0.625 | |
| 11 | 10 | 0 | 7 | ||||
| 12 | 15 | 0 | 5 | 0.200 | 0.800 | 0.500 | |
| 13 | 20 | 0 | 4 | 0.250 | 0.750 | 0.375 | |
| 14 | 25 | 0 | 3 | 0.333 | 0.667 | 0.250 | |
| 15 | 30 | 0 | 2 | 0.500 | 0.500 | 0.125 | |
| 16 | 40 | 1 | 1 |
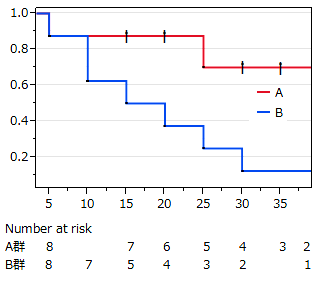 (累積生存率曲線:カプランマイヤー法)
(累積生存率曲線:カプランマイヤー法)
検定:p=0.030(ログランク検定)
解釈:2群の生存時間に差があるとみなす
| Y(目的変数) | A | B | C | C'(ダミー変数) |
|---|---|---|---|---|
| 100 | 40 | 4 | 大 | 1 |
| 90 | 60 | 3 | 大 | 1 |
| 60 | 55 | 7 | 大 | 1 |
| 70 | 40 | 5 | 小 | 0 |
| 40 | 25 | 9 | 小 | 0 |
| 90 | 70 | 2 | 大 | 1 |
| 50 | 40 | 4 | 小 | 0 |
| 110 | 65 | 1 | 大 | 1 |
| 60 | 40 | 7 | 大 | 1 |
| 70 | 50 | 5 | 大 | 1 |
| 70 | 45 | 3 | 小 | 0 |
| 50 | 40 | 4 | 小 | 0 |
| 項 | 推定値 | p値 |
|---|---|---|
| 切片 | 117.3 | 0.004 |
| A | -0.56 | 0.30 |
| B | -7.96 | 0.008 |
| C' | 29.2 | 0.014 |
予測式:Y=117.3-0.56×A-7.96×B+29.2×C'(自由度調整R2乗 0.76、p=0.002)
解釈:アウトカムYに対して、因子Bと因子Cが影響する。Yは、Bが1単位増えると7.96減少し、C'が1であると(Cが大であると)29.2増える。
| Y | 群 | X1ダミー | X2ダミー |
|---|---|---|---|
| 100, 110, 120, 120, 130, 130, 130, 140, 140, 150, 160 | A | 0 | 0 |
| 80, 90, 100, 100, 110, 110, 110, 120, 120, 130, 140 | B | 1 | 0 |
| 90, 100, 110, 110, 120, 120, 120, 130, 130, 140, 150 | C | 0 | 1 |
| 項 | 推定値 | p値 |
|---|---|---|
| 切片 | 130 | 0.0001 |
| X1 | -20 | 0.01 |
| X2 | -10 | 0.19 |
予測式:Y=130-20×X1-10×X2(自由度調整R2乗 0.14、p=0.038)
解釈:分散分析のp値、R2乗値と一致する(②を参照)
係数(推定値)は各群の平均の差となる
A群に比し、B群は20低く(p=0.01)、C群は10低い(p=0.19)
| Y | 群 | X1 | X2 | X3共変量 |
|---|---|---|---|---|
| 100, 110, 120, 120, 130, 130, 130, 140, 140, 150, 160 | A | 0 | 0 | 4, 5, 4, 6, 7, 4, 8, 10, 9, 10, 11 |
| 80, 90, 100, 100, 110, 110, 110, 120, 120, 130, 140 | B | 1 | 0 | 4, 5, 7, 4, 6, 8, 4, 9, 8, 9, 10 |
| 90, 100, 110, 110, 120, 120, 120, 130, 130, 140, 150 | C | 0 | 1 | 12, 10, 8, 11, 13, 10, 12, 14, 11, 12, 16 |
| 項 | 推定値 | p値 |
|---|---|---|
| 切片 | 90.2 | 0.0001 |
| X1 | -18 | 0.0009 |
| X2 | -36 | 0.0001 |
| X3 | 5.6 | 0.0001 |
予測式:Y=90.2-18×X1-36×X2+5.6×X3(自由度調整R2乗 0.63、p=0.0001)
解釈:Yに対して影響をもつ共変量X3によって補正
X1、X2のいずれもが有意となる
A群に比し、B群は18低く、C群は36低い(C群の方がより低下する結果になる)

| Event | 群 | X1ダミー | X2ダミー | X3 |
|---|---|---|---|---|
| 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1 | A | 0 | 0 | 4.5 / 5.5 / 6 / 7 / 6.5 / 6.5 / 6.5 / 7 / 7 / 7.5 / 8 |
| 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0 | B | 1 | 0 | 4 / 4.5 / 5 / 5 / 5.5 / 5.5 / 4.5 / 6 / 6 / 6.5 / 7 |
| 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1 | C | 0 | 1 | 4.5/ 5 / 5.5 / 5.5 / 6 / 6.5 / 6 / 6.5 / 7.5 / 7 / 9 |
| 項 | 推定値 | p値 |
|---|---|---|
| 切片 | -6.04 | 0.09 |
| X1 | -2.57 | 0.054 |
| X2 | -0.075 | 0.94 |
| X3 | 1.10 | 0.047 |
尤度比検定では各パラメータのp値は、X1: 0.03, X2: 0.94, X3: 0.021
イベントの発生率をpとすると、
予測式:log(p/(1-p))= -6.04-2.57×X1-0.075×X2+1.10×X3
解釈:イベント生起にX1(AvsB)、X3が影響しているとみなす
さらに、
e -2.57=0.076は、X1が1単位増加したときのオッズ比
e -0.075=0.92は、X2が1単位増加したときのオッズ比
e 1.10=3.00は、X3が1単位増加したときのオッズ比
統計ソフトに説明変数として”群”と”X3”をそのまま入れた場合、
予測式:log(p/(1-p))= -6.93 +(B:-1.69,C: 0.807,A: 0.882) +1.10×X3となり、値は上記に一致する。
B群: -8.61+1.10×X3と-8.62+1.10×X3
C群: -6.11+1.10×X3と-6.12+1.10×X3
A群: -6.04+1.10×X3と-6.05+1.10×X3
X3だけでロジスティック回帰を行いROC曲線をかくと、
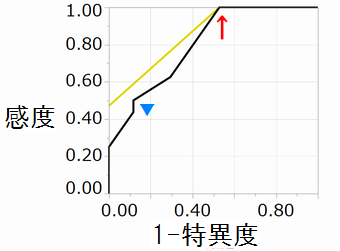
矢印のところで、感度1.0、特異度0.47を与えるX3のカットオフ値5.5、
矢頭のところで、感度0.5、特異度0.88を与えるカットオフ値6.7が定まる。
(感度を優先すべきか(スクリーニングなど)、特異度を優先すべきか(確定診断など)による)